ChatGPT:n julkaisusta on kohta vuosi, ja tyypilliset tavat hyödyntää generatiivista eli luovaa tekoälyä ja erityisesti kielimalleja alkavat hahmottua. Pelkän ChatGPT:n kanssa jutustelu on selvästi vähentynyt alkuhuuman jälkeen, ja erilaisia kielimallien päälle rakennettuja lisäkerroksia ja sovelluksia on joka sormelle. Luovien tekoälymallien kehittäjät ovat tuoneet yleisesti saataville ensimmäisiä multimodaalisia malleja, joille voi syöttää esimerkiksi videon, ääniraidan ja pyynnön tiivistää videon sanoma haikurunon muodossa.
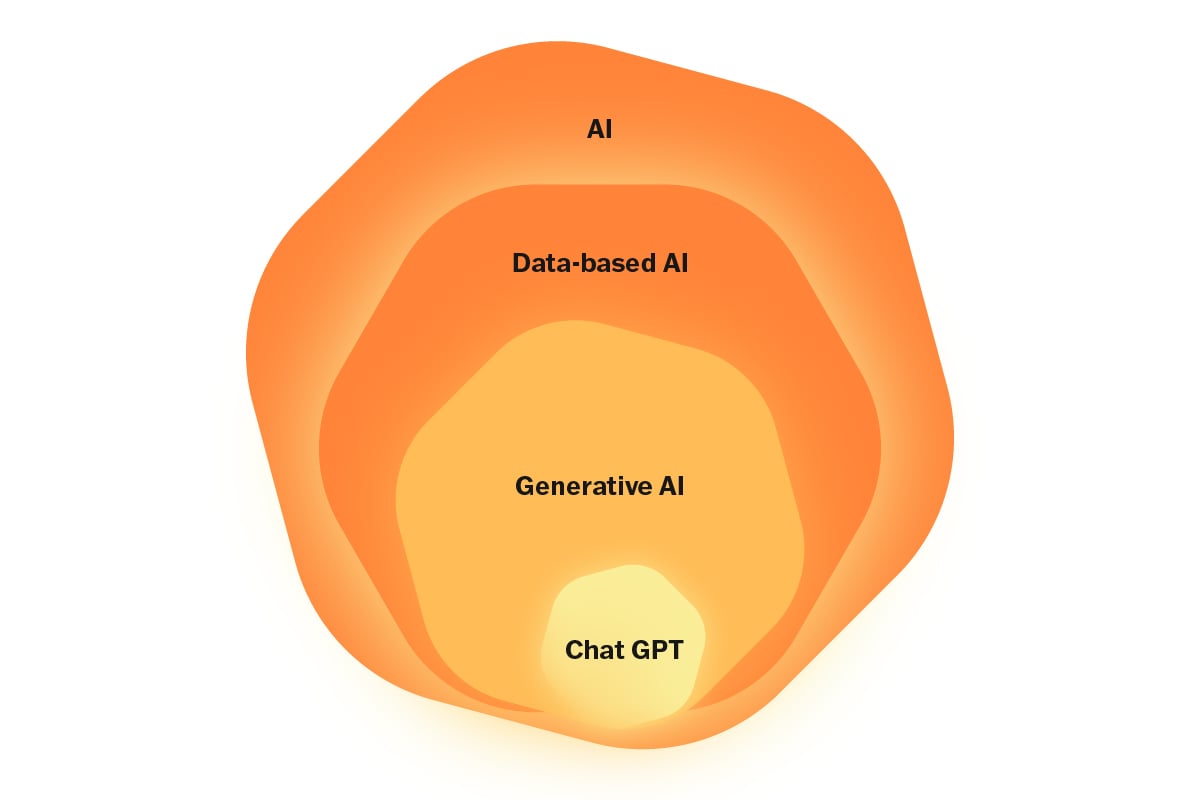
Kuva 1: Tekoälyn kentällä luova tekoäly on osa datapohjaisia menetelmiä, joissa (teko)älykkyys perustuu datasta oppiviin malleihin.
Toistaiseksi valtaosa luovan tekoälyn sovelluksista on kuitenkin yhtä datatyyppiä hyödyntäviä ja erityisesti kielimallien (tekstiä tuottavat tekoälymallit) päälle on muodostunut monia sovelluksia. Yhteistä monille niistä on retrieval augmentation generation (RAG). Sanahirviö ei oikein käänny suoraan suomeksi, mutta periaate on yksinkertainen: kielimallille ei lähetetä pelkkää käyttäjän kirjoittamaa kysymystä, vaan syötettä rikastetaan kysymyksen perusteella haetulla datalla (+ mahdollisilla muilla lisämausteilla, ns. prompt engineering). Samaa tekee toki moni ChatGPT-käyttäjä itsekin kopioidessaan syötteeseen tekstiä muualta ja kirjoittamalla ohjeet ennen kopioimaansa tekstiä.
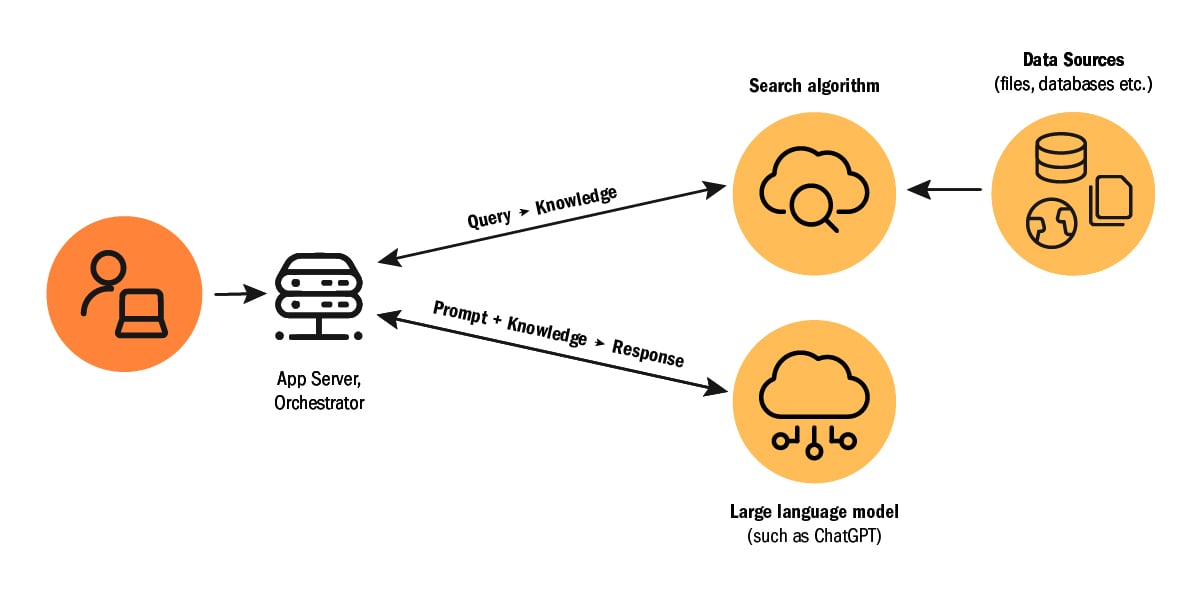
Kuva 2: Esimerkki Retrieval Augmentation Generation -arkkitehtuurista
RAG-sovelluksiin kuuluvat kielimallin ohella seuraavat olennaiset osat:
- Kysymys
- Data
- Hakualgoritmi
Mikä näistä on tärkein, kun halutaan saada hyviä tuloksia? Käyttäjän syöttämään kysymykseen ei juuri voi vaikuttaa kuin yksinkertaisella ohjeistuksella ja silloinkin syötteet vaihtelevat suuresti. Hakualgoritmeja löytyy kourallinen valmiina ja ne on äkkiä käyty läpi. Jäljelle jää siis tietoaineisto ja sen rakenne.
Datan laatu ratkaisee
Tietoaineiston laatu ja sopivan aineiston rajaaminen ovat siis avainasemassa hyvien tulosten saamisessa. Havainnollistetaan tilannetta alla esimerkillä.
Monessa yrityksessä halutaan kokeilla ChatGPT + Microsoft SharePoint -yhdistelmää, jonka tavoitteena on tuoda pirstaloitunut tieto käyttäjän ulottuville ilman työlästä segmentointia ja muuta jumppaa. Kielimalleilla on kuitenkin rajallinen muisti, eivätkä ne kykene käsittelemään koko aineistoa kerralla. Tällöin pitää valikoida, mikä osa SharePointin sisällöstä lähetetään käsiteltäväksi yhdessä kysymyksen kanssa.
Tätä voi kokeilla itse kirjoittamalla kysymyksen SharePointin hakuun ja tarkastelemalla ensimmäistä kolmea hakutulosta. Käytin esimerkkinä kysymystä ”Millä ehdoilla esihenkilö voi perua palkattoman vapaan sen myöntämisen jälkeen?” (Haluan varmistaa, ettei mikään tule minun ja marraskuun lomareissun väliin). Sisälsivätkö ensimmäiset kolme tulosta vastauksen kannalta olennaisia tietoja?

Kuva 3: Kuvakaappaus epäonnistuneesta SharePoint-hausta
No, eivät.
Eli käytännössä hyviä osumia ei ole ja SharePointin haku ei siksi palauta tuloksia. Kielimalli tietysti vastaisi kysymykseen, ellei konfiguroinnissa ole todella tarkkana.
Kokeillaan hakua vielä toisen kerran, tällä kertaa hakusanoilla ”palkaton vapaa”.

Kuva 4: Epäonnistunut haku vol. 2
Nyt haku palauttaa tuloksia, mutta ne eivät ole yleisiä ohjeistuksia vaan jotain aivan muuta. Kielimallille lähetettävä data ei siis ole riittävän laadukasta, minkä takia tuloksetkaan eivät voi olla sitä.
Haun kannalta olennaisten sanojen poimiminen käyttäjän kysymyksestä ja haun kohdistaminen rajatumpaan aineistoon ovat molemmat tapoja parantaa kielimallille lähetettävän datan laatua. Datan laatu korostuu entisestään, kun siirrytään monimutkaisempiin käyttötapauksiin, joissa tieto päivittyy usein, kysymyksen kannalta olennaiset asiat löytyvätkin metadatasta ja oikean tiedon rajaaminen kullekin käyttäjälle on kaikkea muuta kuin yksinkertaista.
Perusta jonka päälle tekoälyä voi rakentaa
Datan laatu on keskeistä paitsi luovan tekoälyn hyödyntämisessä myös raportoinnissa, analytiikassa, koneoppimisessa, optimoinnissa ja monessa muussa teknologiassa, joita organisaatiot hyödyntävät tiedolla johtamisessa. Tämän vuoksi viimeisen vuosikymmenen aikana on viety maaliin useita tietoalustahankkeita ja kohdistettu entistä enemmän resursseja sovellusten perustan kuntoon laittamiseen. Perusta on: oikea data, oikeille henkilöille, oikeaan aikaan, oikeassa paikassa.
Kansainvälinen markkinatutkimusyhtiö IDC kirjoitti äskettäin blogissaan, miten onnistua luovan tekoälyn hyödyntämisessä. IDC:n mukaan perusta rakennetaan neljän pilarin varaan:
- Vastuulliset menettelytavat tekoälyn hyödyntämisessä (AI Policy) – Säädösten, kuten GDPR:n (ja tulevan EU AI Act:in) huomiointi ja käytettävien mallien selitettävyys ovat hygieniatekijöitä, joiden tulee olla kunnossa.
- Tekoälystrategia ja etenemissuunnitelma – Tekoälystrategiaan kuuluvat luovan tekoälyn kokeilujen, kuten proof-of-concept (PoC) -hankkeiden suunnittelu, sekä päätökset sen osalta, millä kriteereillä kokeiluja viedään eteenpäin, miten niistä jatketaan tuotantoon ja miten strategiaa päivitetään, kun kokeiluista saadaan uutta tietoa.
- AI-sovellusten arkkitehtuuri – Millaiseen teknologiaympäristöön AI-sovellukset upotetaan? PoC-hankkeiden yksi tavoite on lisätä ymmärrystä ja tukea AI-sovellusten alustan suunnittelua.
- Osaamisen kasvattaminen – Harvan organisaation henkilöstöllä on valmiiksi kaikki tekoälyn hyödyntämiseen tarvittavat taidot. AI-osaajien rekrytoinnilla ja nykyhenkilöstön osaamista kasvattamalla varmistetaan, että organisaatio saa uudesta teknologiasta täyden hyödyn irti.
Nämä neljä pilaria kuitenkin seisovat tietoalustan päällä ja IDC:n tutkimusten mukaan se alusta ei ole teräsbetonia, vaan jotain suon ja saven välimaastosta:
- 82% organisaatioista kärsii siiloutuneesta datasta
- 41%:n mukaan data muuttuu nopeammin kuin he voivat pysyä mukana
- 24% ei luota omaan dataansa
- 29%:lla on ongelmia datan laadun kanssa
Miten mahtaa AI:n hyödyntäminen edetä esimerkiksi niissä 24 prosentissa organisaatioita, jotka eivät luota omaan dataansa?
On kuitenkin hyvin ymmärrettävää, että tilanne on mikä on. Datan saaminen kuntoon versus datan hyödyntäminen on klassinen muna vai kana ongelma. Datan heikko laatu vaikeuttaa datan hyödyntämistä, jolloin AI-hankkeet jäävät parkkiin, kunnes ”perusasiat ovat kunnossa”. Datan laadun parantamista taas ei useinkaan tehdä vain itsensä vuoksi, koska organisaatiossa ei ole painetta laittaa dataa kuntoon, jos ”mikään sovellus ei käytä sitä”.
Yritysjohdolta vaaditaan siis näkemyksellisyyttä ja strategisia päätöksiä tekoälyn hyödyntämisestä. Oman osaamisen kehittäminen on avainasemassa, ja pätevä kumppani on usein se piste i:n päällä, jolla saa nostettua itsensä markkinan kärkeen.
Voimmeko auttaa sinun organisaatiotasi hyödyntämään paremmin dataa ja tekoälyä? Ota meihin yhteyttä, niin laitetaan hommat rullaamaan.
Janne Sipilä: janne.sipila@twoday.com, +358 50 486 1131